Big Data Text Analysis
Home -- Download -- Instructions -- FAQ
Big Data Text AnalysisHome -- Download -- Instructions -- FAQ |
There are three types of word association analyses that can be applied to texts gathered by Mozdeh. These can detect the following.
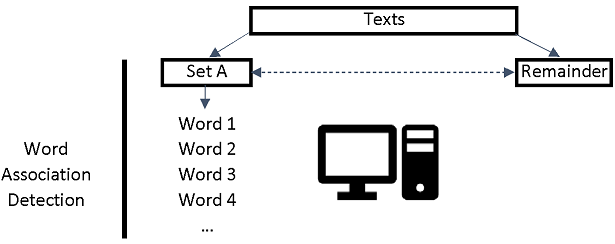
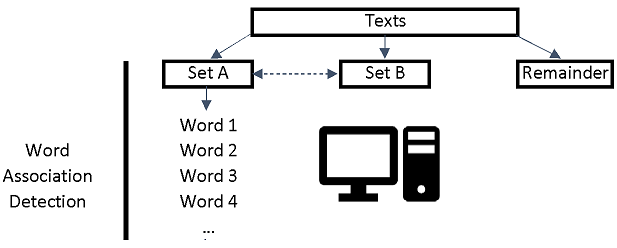
These tests all rely on the same statistical approach.
The tests are described in detail below for queries and on other pages for gender, country [Twitter only], time, retweets/likes/citations, sentiment, and users/source queries. They can also be applied to combinations (e.g., positive tweets from UK females vs. positive tweets from US females).
It can be useful to identify the words that are unusually common in posts that match a particular query/filter because they may point to important aspects of the topic discussed. This splits the data into two parts: A and the rest. It finds words that occur more often in A than in the rest of the texts. This is achieved as follows.
In the example below the query is spring and no filters were selected. At the top of the list, ignoring spring, the term roll associates with spring because 23.4% of the texts containing "spring" also contain "roll". In contrast, 0.7% of the remaining posts contain "roll". The chi-square is a statistical test of this association.
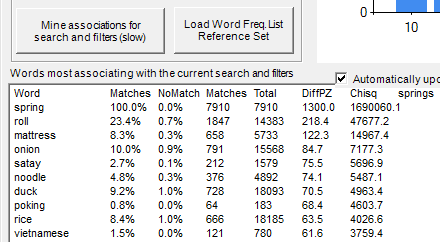
The chi square value indicates how statistically significant the difference is between the frequency of the terms in the topic-specific collection of texts compared to all texts collected, with higher values indicating more significant results.
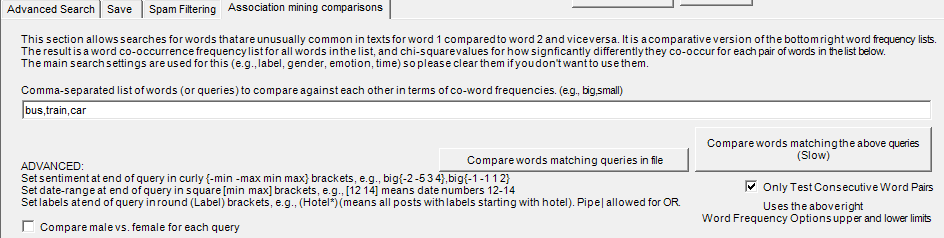
The above methods find words that associate with one term and/or filters compared to the rest of the project. You might want to compare a set of queries against each other. This splits the data into two parts: A and B. It finds words that occur more often in A than B and words that occur more often in B than in A. To do this, select the Association mining comparisons tab and enter your queries in the new text box, separated by commas. Then click Compare words matching the above queries (slow). The results will be saved into a set of files (not displayed on screen) that need to be loaded into a spreadsheet to be analysed. The list below will find words that associate with bus in comparison to train, with bus in comparison to car, and train in comparison to car.
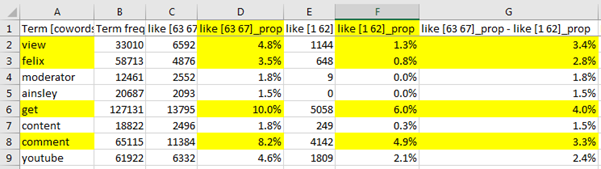
After loading into a spreadsheet and formatting, you might see results like below. This is for the query like [1 62] against the query like [63 67]. It is a comparison of terms associating with the term like earlier posts (months 1 to 62) against words associating with it in later posts (months 63 to 67). Square boxes can be used to delimit dates with queries in this way. Benjamini-Hochberg statistics are given for these for the whole set of tests at once (i.e., not separately for positive an negative).
To identify words that associate with your entire project, a generic list of word frequencies is needed that the topic words can be compared against. This should be a plain text file with a list of words and their frequencies from a common, generic collection of texts. A file of word frequencies for a large collection of UK and Ireland tweets will be used unless you have your own. Click the Load Word Freq List Reference Set button on the bottom right of the screen, follow the instructions, clear the search box, and click Mine associations for search and/or filters (slow). The results will appear in the text box below it.
Mozdeh uses a 2x2 chi-squared statistical test to assess the statistical significance of the difference between the proportions of texts containing each word in the two sets compared. When many statistical tests are run at the same time then the chances of drawing a false conclusion from at least one of them is high. This problem occurs with Mozdeh when it calculates many chi-squared values at the same time (controlling the familywise error). To reduce the risk of falsely believing that a term is significant, Benjamini-Hochberg procedure is used by Mozdeh. This tests all the words at once and reports the significant terms using a single test, controlling the risk of false positives due to multiple tests. To use this procedure, look at the stars in the right hand column (below). One star * is significant at the (familywise) 5% level, two stars ** is significant at the (familywise) 1% level and three stars *** is significant at the (familywise) 0.1% level.
Technical note: The total number of tests used in the Benjamini-Hochberg method is the number of words that have a high enough frequency to be capable of generating a statistically significant result. This is normally the number of words that occur in at least 2 or 3 different posts.
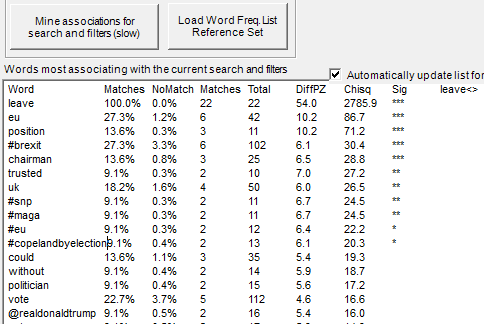
The example below illustrates the star system. At the 5% level, 11 terms are statistically significant (the top 11 terms, from 'leave' to '#copelandbyelection'). At the 1% level, 9 terms are statistically significant (the top 9 terms). At the 0.1% level, 5 terms are statistically significant (the top 5 terms).
| Made by the University of Wolverhampton during the CREEN and CyberEmotions EU projects and updated at the University of Sheffield. |